

Hiperpowierzchnia błędu w procesie uczenia sieci
Dla zrozumienia istoty trudności, na jakie natrafia się przy modelowaniu nieliniowych zależności przy użyciu sieci neuropodobnych pomocna może być koncepcja (wzmiankowanej już wcześniej) hiperpowierzchni błędu. Każda z 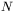 wag i wartości progowych sieci traktowana jest jako jeden z wymiarów przestrzeni. W ten sposób komplet danych o sieci, obejmujący wszystkie wolne parametry modelu, może być zamieniony na jej stan, reprezentowany przez
wag i wartości progowych sieci traktowana jest jako jeden z wymiarów przestrzeni. W ten sposób komplet danych o sieci, obejmujący wszystkie wolne parametry modelu, może być zamieniony na jej stan, reprezentowany przez 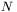 parametrów, zaś każdy stan sieci, wyznaczony przez aktualne wartości jej
parametrów, zaś każdy stan sieci, wyznaczony przez aktualne wartości jej 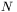 parametrów może być traktowany jako punkt na
parametrów może być traktowany jako punkt na 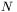 -wymiarowej hiperpłaszczyźnie. Przy rysowaniu powierzchni błędu
-wymiarowej hiperpłaszczyźnie. Przy rysowaniu powierzchni błędu 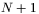 wymiarem (zaznaczanym jako wysokość ponad wspomnianą wyżej, płasko rozciągającą się hiperpowierzchnią) jest błąd, jaki sieć popełnia, rozwiązując postawione zadanie (rys. 4).
wymiarem (zaznaczanym jako wysokość ponad wspomnianą wyżej, płasko rozciągającą się hiperpowierzchnią) jest błąd, jaki sieć popełnia, rozwiązując postawione zadanie (rys. 4).
)
Rysunek 4. Uczenie jako proces minimalizacji błędu w przypadku sieci liniowej
(aby obejrzeć powiększony rysunek, kliknij w miniaturkę)
pojęcie błędu Poświęćmy trochę uwagi interpretacji pojęcia błędu, gdyż jest to pojęcie o kluczowym znaczeniu. Prawidłowo wyznaczony błąd jest "motorem napędowym" procesu uczenia sieci (gdyż uczenie polega na systematycznym zmniejszaniu błędu), zaś uczenie, jak już wielokrotnie było mówione, ma kluczowe znaczenie dla całej techniki sieci neuropodobnych. Czym wobec tego jest błąd? Czasem ma on oczywistą interpretację i jest łatwy do wyznaczenia, np. gdy zadaniem sieci jest obliczenie jednej konkretnej wartości wyjściowej i można bezpośrednio porównać wartość jaką sieć obliczyła z wartością prawidłową (która jest znana w przypadku danych uczących, ponieważ zgodnie z definicją zawierają one, obok wartości sygnałów wejściowych do budowanego modelu, także wzorce jego poprawnych odpowiedzi). Innym razem trzeba się dopiero umówić co do sposobu reprezentowania błędu — np. gdy sieć ma rozpoznawać pewne wejściowe obiekty i z ewentualnymi pomyłkami trzeba związać funkcję "kary", zależną od tego, jaki obiekt był rozpoznawany i jakie podano błędne rozpoznanie (z reguły nie każda pomyłka jest tak samo kosztowna). W jeszcze innych sytuacjach można funkcję błędu związać z wartością uśrednioną — np. po wielu sygnałach wyjściowych albo po wielu zadaniach (mogą one tworzyć razem tzw. epokę procesu uczenia). Niezależnie jednak od tego, jak zdefiniujemy błąd, zawsze możemy go wyznaczyć, tzn. możemy stwierdzić, że taki oto błąd wykazuje sieć mająca takie właśnie parametry. Jeśli parametry sieci potraktujemy jako współrzędne, to z każdym stanem wytrenowania sieci związany będzie pewien punkt zaznaczony na 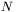 -wymiarowej hiperpowierzchni. W punkcie tym możemy zaznaczyć wartość błędu popełnianego przez sieć — jako wysokość na jakiej ponad tym punktem zawiesimy powierzchnię błędu.
-wymiarowej hiperpowierzchni. W punkcie tym możemy zaznaczyć wartość błędu popełnianego przez sieć — jako wysokość na jakiej ponad tym punktem zawiesimy powierzchnię błędu.
Powierzchnię tę konstruujemy w ten sposób, że dla każdego możliwego punktu (czyli dla każdego zestawu wag i progów, jeśli są one osobno wyznaczane w neuronach) wyznaczamy błąd, który może zostać narysowany jako punkt w przestrzeni 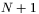 wymiarowej. Stan sieci, wynikający z aktualnego zestawu jej parametrów, lokuje ten punkt na wspomnianej wyżej
wymiarowej. Stan sieci, wynikający z aktualnego zestawu jej parametrów, lokuje ten punkt na wspomnianej wyżej 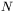 -wymiarowej hiperpłaszczyźnie, zaś wartość błędu, jaki popełnia sieć dla tych właśnie wartości parametrów, stanowi wysokość umieszczenia punktu ponad tą płaszczyzną. Gdybyśmy opisaną procedurę powtórzyli dla wszystkich możliwych wartości kombinacji wag i progów sieci, wówczas otrzymalibyśmy "chmurę" punktów, rozciągających się ponad wszystkimi punktami
-wymiarowej hiperpłaszczyźnie, zaś wartość błędu, jaki popełnia sieć dla tych właśnie wartości parametrów, stanowi wysokość umieszczenia punktu ponad tą płaszczyzną. Gdybyśmy opisaną procedurę powtórzyli dla wszystkich możliwych wartości kombinacji wag i progów sieci, wówczas otrzymalibyśmy "chmurę" punktów, rozciągających się ponad wszystkimi punktami 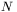 -wymiarowej hiperpłaszczyzny parametrów sieci. Jeśli punktów takich mieli byśmy nieskończenie dużo, to stwierdzilibyśmy, że tworzą one właśnie rozważaną tu powierzchnię błędu. Niestety, poza prostymi przykładami (o znaczeniu wyłącznie dydaktycznym) takie pełne wyznaczenie powierzchni błędu jest niewykonalne, gdyż wiązałoby się z nakładem prac obliczeniowych o wielkości trudnej do zaakceptowania. Dlatego pojęcie powierzchni błędu ma wyłącznie poglądowe znacznie — co nie zmniejsza jego przydatności.
-wymiarowej hiperpłaszczyzny parametrów sieci. Jeśli punktów takich mieli byśmy nieskończenie dużo, to stwierdzilibyśmy, że tworzą one właśnie rozważaną tu powierzchnię błędu. Niestety, poza prostymi przykładami (o znaczeniu wyłącznie dydaktycznym) takie pełne wyznaczenie powierzchni błędu jest niewykonalne, gdyż wiązałoby się z nakładem prac obliczeniowych o wielkości trudnej do zaakceptowania. Dlatego pojęcie powierzchni błędu ma wyłącznie poglądowe znacznie — co nie zmniejsza jego przydatności.



