

Sieci liniowe
Ogólna zasada stosowana w nauce głosi, że w przypadku gdy istnieje możliwość wyboru pomiędzy modelem prostszym i bardziej złożonym, należy zawsze preferować model prostszy — o ile oczywiście ten drugi nie dopasowuje się znacząco lepiej do posiadanych danych. Stosując terminy charakterystyczne dla aproksymacji funkcji, można stwierdzić, że najprostszym, i z wielu względów najwygodniejszym, modelem aproksymującym matematycznie pewną zaobserwowaną praktyczną zależność jest zawsze model liniowy. Stosując terminologię związaną z sieciami neuropodobnymi można z kolei stwierdzić, że model liniowy jest reprezentowany przez sieć nie posiadającą warstw ukrytych, zaś neurony znajdujące się w jej warstwie wyjściowej są w pełni liniowe — tzn. są to neurony, w których łączne pobudzenie wyznaczane jest jako liniowa kombinacja wartości wejściowych i które posiadają liniową funkcję aktywacji. W modelu takim funkcją dopasowywaną do posiadanych danych jest hiperpłaszczyzna, a dokładniej — 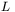 hiperpłaszczyzn, gdzie
hiperpłaszczyzn, gdzie 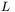 jest liczbą neuronów. Należy znaleźć właściwe położenie i właściwe nachylenie każdej takiej hiperpłaszczyzny. Model liniowy jest zwykle reprezentowany równaniem:
jest liczbą neuronów. Należy znaleźć właściwe położenie i właściwe nachylenie każdej takiej hiperpłaszczyzny. Model liniowy jest zwykle reprezentowany równaniem:
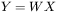 |
[1] |
gdzie: 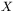 jest wektorem sygnałów wejściowych (przyjmijmy, że ma on
jest wektorem sygnałów wejściowych (przyjmijmy, że ma on 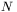 elementów, co odpowiada liczbie danych wejściowych determinujących rozważany problem),
elementów, co odpowiada liczbie danych wejściowych determinujących rozważany problem), 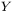 jest wektorem sygnałów wyjściowych (przyjmijmy, że ma on
jest wektorem sygnałów wyjściowych (przyjmijmy, że ma on 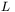 elementów, co odpowiada liczbie neuronów w sieci, a równocześnie wyznacza liczbę uzyskiwanych z sieci danych wyjściowych, determinujących rozważany problem),
elementów, co odpowiada liczbie neuronów w sieci, a równocześnie wyznacza liczbę uzyskiwanych z sieci danych wyjściowych, determinujących rozważany problem), 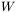 jest macierzą współczynników wagowych (macierz ta składa się z tylu wierszy, ile jest neuronów w sieci, oraz ma tyle kolumn, ile jest sygnałów wejściowych; element
jest macierzą współczynników wagowych (macierz ta składa się z tylu wierszy, ile jest neuronów w sieci, oraz ma tyle kolumn, ile jest sygnałów wejściowych; element 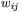 odpowiada współczynnikowi wagowemu występującemu w
odpowiada współczynnikowi wagowemu występującemu w 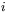 -tym neuronie na jego
-tym neuronie na jego 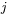 -tym wejściu).
-tym wejściu).
zalety korzystania z sieci neuronowych Sieci neuronowe liniowe stanowią wygodne narzędzie, możliwe do bezpośredniego zastosowania (np. w przetwarzaniu sygnałów do filtracji zakłócających szumów z automatycznym, w trakcie uczenia dobieranym, pasmem przepustowym sygnału), a także mogą stanowić dobry punkt odniesienia, z którym porównuje się jakość innych (nieliniowych) sieci neuropodobnych. Warto próbować korzystać z sieci liniowych, gdy tylko jest to możliwe, ponieważ zawsze jest szansa, że aktualnie rozwiązywany problem — uważany pierwotnie za bardzo złożony — może zostać w rzeczywistości rozwiązany równie dobrze przez sieć liniową jak i przez inną sieć neuronową, ale o złożonej nieliniowej strukturze. Bywają także dodatkowe okoliczności skłaniające do stosowania właśnie modeli liniowych. W szczególności, jeśli zbiór uczący składa się tylko z niewielu przypadków (występuje brak danych potrzebnych do uczenia sieci), to zastosowanie bardziej złożonych modeli nie jest w praktyce możliwe — nie uda się skutecznie nauczyć złożonej sieci przy użyciu niewielkiej liczby danych uczących. Wtedy korzystanie z modelu liniowego (oraz odpowiednio z liniowej sieci neuronowej) jest najwłaściwszą metodą rozwiązania problemu, o ile w ogóle da się go rozwiązać. Należy pamiętać, że brak wystarczającej liczby danych uczących (lub niedobór danych uczących wnoszących dostatecznie ważne informacje, dostatecznie szeroko charakteryzujące istotę rozwiązywanego zadania) może całkowicie wykluczyć użycie sieci neuronowej, zarówno liniowej, jak i nieliniowej.
czy warto stosować sieci z wieloma warstwami ukrytymi Jednym z głównych ograniczeń, jakim podlegają sieci liniowe, jest bezcelowość stosowania w tych sieciach struktury zawierającej wiele warstw neuronów, a zwłaszcza warstw ukrytych (patrz rys. 3). Wynika to z faktu, że klasa odwzorowań, możliwych do uzyskania w sieciach wielowarstwowych, jest dla sieci liniowych dokładnie taka sama, jak w sieci jednowarstwowej. Prześledźmy to na prostym przykładzie.Wyobraźmy sobie sieć liniową, mającą na wejściu sygnał (wektor) 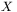 , który po przetworzeniu przez pierwszą warstwę sieci (opisaną macierzą wag
, który po przetworzeniu przez pierwszą warstwę sieci (opisaną macierzą wag 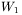 ) staje się sygnałem (wektorem) pośrednim
) staje się sygnałem (wektorem) pośrednim 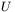 i trafia na drugą warstwę sieci posiadającą zestaw wag dany macierzą
i trafia na drugą warstwę sieci posiadającą zestaw wag dany macierzą 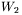 , a sygnał wyjściowy
, a sygnał wyjściowy 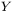 (rozwiązanie) pobierany jest dopiero z wyjścia tej drugiej warstwy. Mamy wtedy do czynienia z dwoma przekształceniami:
(rozwiązanie) pobierany jest dopiero z wyjścia tej drugiej warstwy. Mamy wtedy do czynienia z dwoma przekształceniami:
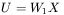 |
[2] |
i
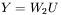 |
[3] |
których właściwości są kształtowane przez dwie macierze podlegające procesowi uczenia: 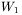 oraz
oraz 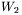 . Na pozór mamy w tym modelu więcej stopni swobody i możemy (pozornie!) dopasować jego kształt do bardziej złożonego problemu, jednak zgodnie z zasadami rachunku macierzowego możemy dokonać podstawienia:
. Na pozór mamy w tym modelu więcej stopni swobody i możemy (pozornie!) dopasować jego kształt do bardziej złożonego problemu, jednak zgodnie z zasadami rachunku macierzowego możemy dokonać podstawienia:
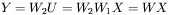 |
[4] |
Okazuje się więc, że zamiast uczenia dwóch macierzy wag 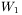 oraz
oraz 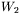 możemy się ograniczyć do uczenia jednej macierzy
możemy się ograniczyć do uczenia jednej macierzy 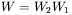 występującej w równoważnej sieci jednowarstwowej, uzyskując dokładnie ten sam efekt. Zatem wprowadzanie dalszych warstw w sieci liniowej nie daje żadnych korzyści i jeśli jakieś zadanie jest zbyt trudne dla sieci liniowej jednowarstwowej, to nie da się uzyskać większej "inteligencji" sieci poprzez dodawanie jej dodatkowych warstw. Odmienna sytuacja jest w sieciach nieliniowych. W sieciach takich sygnał uzyskiwany na wyjściu pierwszej warstwy opisywany będzie przez wzór:
występującej w równoważnej sieci jednowarstwowej, uzyskując dokładnie ten sam efekt. Zatem wprowadzanie dalszych warstw w sieci liniowej nie daje żadnych korzyści i jeśli jakieś zadanie jest zbyt trudne dla sieci liniowej jednowarstwowej, to nie da się uzyskać większej "inteligencji" sieci poprzez dodawanie jej dodatkowych warstw. Odmienna sytuacja jest w sieciach nieliniowych. W sieciach takich sygnał uzyskiwany na wyjściu pierwszej warstwy opisywany będzie przez wzór:
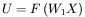 |
[5] |
gdzie funkcja 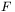 opisuje nieliniowe przekształcenie zachodzące we wszystkich neuronach sieci. Podobnie w drugiej warstwie mamy zależność:
opisuje nieliniowe przekształcenie zachodzące we wszystkich neuronach sieci. Podobnie w drugiej warstwie mamy zależność:
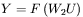 |
[6] |
W tym przypadku złożenie opisanych dwóch odwzorowań daje niemożliwą do zredukowania formułę:
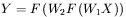 |
[7] |
wskazującą wyraźnie, że każda kolejna dodana warstwa nieliniowych neuronów w sposób znaczący zwiększa złożoność modelu i podnosi stopień jego adaptowalności.



