

Rozdział 17
Analiza danych: analiza dyskryminacyjna, czynnikowa i skupień
Do segmentacji rynku wybrano analizę dyskryminacyjną dlatego, że:
zmienne niezależne stanowiły skategoryzowane wartości wieku, dochodów i stażu pracy
zmienne niezależne są zmiennymi ciągłymi
zmienna zależna jest wielowariantową zmienną (kategorialną)
stanowi odpowiednik analizy regresji
Standaryzacja współczynników funkcji dyskryminacyjnej:
nie była w tym przypadku konieczna
umożliwiła porównywanie względnego wpływu różnomianowych zmiennych niezależnych
jest zawsze stosowana w każdej analizie regresji i dyskryminacji
powoduje, że jednostka miar zmiennych jest zawsze równa 1,00
| Faktyczna klasyfikacja | Przewidywana klasyfikacja | ||
|---|---|---|---|
| segment 1 | segment 2 | segment 3 | |
| Segment 1 | 200 | 10 | 10 |
| Segment 2 | 5 | 150 | 10 |
| Segment 3 | 5 | 10 | 100 |
80%
90%
95%
100%
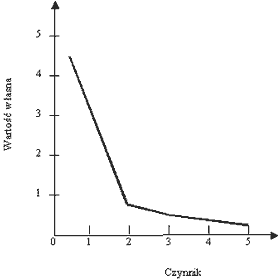
Test osypiska
1 główną składową
2 główne składowe
3 główne składowe
4 główne składowe
Test osypiska
20% niewyjaśnionej zmienności zmiennych pierwotnych
40% niewyjaśnionej zmienności
50% niewyjaśnionej zmienności
60% niewyjaśnionej zmienności
W procesie wyodrębnienia czynników zastosowano:
regułę "wartości własnej >1"
80% wyjaśnianej wariancji
regułę "wartości własnej >4"
regułę testu osypiska
Maksymalna liczba głównych składowych w tej analizie wynosi:
2
3
5
10
| Stwierdzenie ze skali Likerta | Czynnik 1 | Czynnik 2 |
|---|---|---|
| X1 | 0,71 | 0,50 |
| X2 | 0,23 | 0,86 |
| X3 | 0,09 | 0,36 |
| X4 | 0,81 | 0,31 |
| X5 | 0,72 | 0,10 |
| X6 | 0,56 | 0,44 |
| X7 | 0,78 | 0,47 |
| X8 | 0,03 | 0,93 |
| X9 | 0,21 | 0,88 |
| X10 | 0,95 | 0,50 |
1, 4, 5, 7, 10
3, 8
1, 2, 3, 4, 5
6, 7, 8, 9, 10
| Stwierdzenie ze skali Likerta | Czynnik 1 | Czynnik 2 |
|---|---|---|
| X1 | 0,71 | 0,50 |
| X2 | 0,23 | 0,86 |
| X3 | 0,09 | 0,36 |
| X4 | 0,81 | 0,31 |
| X5 | 0,72 | 0,10 |
| X6 | 0,56 | 0,44 |
| X7 | 0,78 | 0,47 |
| X8 | 0,03 | 0,93 |
| X9 | 0,21 | 0,88 |
| X10 | 0,95 | 0,50 |
3, 4, 5
2, 8, 9
1, 2, 3, 4, 5
6, 7, 8, 9, 10
Drukuj




